AI Agent 돌풍과 AI Agent 커뮤니티
LLM 봇들의 돌풍 현상을 지켜보며 개인적인 단상을 정리한 글 입니다.
2026-02-05 19:57
19분

지난 2026년 1월 말경, AI Agent인 OpenClaw가 전세계적인 돌풍을 일으켰습니다. OpenClaw는 오스트리아 개발자인 Peter Steinberger가 자신이 사용하는 Claude Code를 이용해 개발한 AI Agent 패키지입니다.
처음에는 Claudbot이라는 이름으로 출시를 했는데 Claude 모델을 개발한 Antropic社로부터 이름에 대한 이슈 제기가 있어 OpenMolt로 이름을 변경했다가 최종적으로 OpenClaw로 리브랜딩했고, 2026년 2월초까지 이를 유지하고 있습니다.
지금까지 LLM 모델을 기반으로 여러가지 Agent들이 출시되었고, 거대 테크 기업에서도 자신들의 Agent를 배포하기도 했으나, OpenClaw는 이렇게 뛰어난 확장성과 편리함, 그리고 독창성으로 인해 전세계 개발자들은 물론이고, 일반 LLM 사용자들로부터 엄청난 호응을 받게 되었습니다.
간단한 통합 패키지 설치 지원, 자신이 평소 즐겨 사용하던 메신저에 연동하여 AI 모델에 질의/명령할 수 있도록 편의 기능을 지원합니다. 물론 자체 CLI 또는 내장된 OpenWebUI를 통해서 자신이 사용하는 로컬 LLM 또는 클라우드 LLM API와 연동하여 사용할 수 있습니다.
대부분의 기능들을 기존에도 사용할 수 있었지만 OpenClaw를 설치하면 자유롭게 자신의 컴퓨터 자원을 LLM에게 내어주고, 본인이 사용하는 각종 클라우드 서비스에 접근하도록 해서 작업을 수행할 수 있습니다. 자신을 대신해서 이메일을 발송하고 문자를 전송하며, 스케줄을 등록하고, 주어진 시간에 자신을 위해 다시 알림을 보낼 수 있습니다.
무엇보다도 OpenClaw의 가장 독창적인 부분은 메모리 관리입니다. 거대 테크 기업들이 자신들만의 방식으로 사용자와의 인터랙션을 장기 기억 혹은 단기 기억 정보로 저장하고 필요할 때마다 해당 정보를 LLM 모델에 던져 사용자의 질의와 함께 처리하고 있습니다. OpenClaw의 경우에는 MEMORY.md 마크다운 파일 및 ./memory/ 하위 폴더에 매일마다 파일을 생성해서 기억해야 할 정보를 저장하게 됩니다.
또한, 메모리 탐색은 벡터 검색과 키워드 검색을 적절하게 조합하며, 검색 효율성을 위해 청킹을 도입했으며, 토큰 비용을 줄이기 위해 정보의 양이 거대해지면 정보를 일정 수준 토큰으로 요약하며 기억의 큰 손실 없이 사용자와의 인터랙션을 이어갈 수 있도록 설계가 되어 있습니다.
더 다듬고 발전시킨다면, LLM 모델의 메모리 관리 부분의 주요 방식 중 하나로 자리매김 할 수 있을 것으로 보입니다.
OpenClaw의 등장으로 AI Agent를 연동하여 서로 소통하게 하고자 하는 실험이 등장했습니다. 미국에서는 MoltBook이라는 영어 기반의 AI Agent 전용 커뮤니티가 등장하고 엄청난 호응을 얻었습니다.
한국에서도 MoltBook의 등장이 있은 후 얼마 지나지 않아, 봇마당, 머슴닷컴과 같이 AI Agent를 연동하여 일정 시간 주기로 글을 읽고 등록하거나 댓글을 달도록 유도하는 서비스들이 생겨났습니다.
원리는 매우 간단합니다. 게시글의 조회나 등록을 위한 REST API의 상세 스펙과 커뮤니티 서비스 내에서 사용해야 하는 말투 및 지침등을 정리하여 SKILL.md 및 GUIDE.md 파일로 만들어 사이트에 서빙한 후, LLM 모델 (AI Agent)에 해당 주소를 던져주면 문서의 내용을 읽고 파악해서 API를 호출해서 글을 등록하게 됩니다.
MoltBook은 Agent 정보 등록을 거치고 API Key 등 credential 정보를 저장하여 일관된 Identity로 활동하게 됩니다. 한국의 머슴닷컴은 고정된 Identity없이 간단한 작업증명 과정을 거쳐 API를 통해 글을 등록하게 됩니다.
오픈된 REST 방식의 API를 통해 조회, 등록 등의 활동이 가능하며 보안이 허술해 보이는 것이 사실입니다. 한국의 여러 AI Agent 전용 커뮤니티들과 비교하면 처음 만들어진 MoltBook의 API가 좀 더 다양하고 잘 설계된 것으로 보입니다.
국내 커뮤니티들의 경우 바이브코딩을 통해 빠른 시일 내에 카피캣 형태로 만들어진 것과 달리 MoltBook은 인간 개발자가 에이전트의 도움을 받아 개발되었으며 Github의 공개 Repository에서 여러 개발자들의 지원과 피드백으로 발전해 가고 있다는 점에서 상당히 많은 차이가 있어 보입니다.
미국의 MoltBook은 2026년 2월 5일 현재 약 1,600,000개 이상의 Agent가 등록되어 글을 올리고 있습니다. 등록되는 글의 내용은 당연하겠지만, LLM 모델이 만들어 내는 의미없는 텍스트부터 광고글, 추상적인 글, 푸념 글 등이 대부분 입니다.
앞서 언급했듯 별도의 AI Agent를 검증하는 과정이 없거나 매우 간소하기 때문에 사람이 직접 API를 통해 등록하는 경우도 심심치 않게 보이고 있습니다.
국내에서 최근 AI Agent 커뮤니티로 주목을 받고 있는 한국어 기반 모 커뮤니티 서비스의 경우, 별도의 Agent 등록 과정 없이 간단한 PoW (작업 증명)을 통해 토큰을 발행하고 있습니다.
인간으로서 글을 게시할 수 있는 웹서비스를 간단하게 구축하고 테스트 해보고자 다음과 같이 설계 전략을 짰습니다.
httpOnly 쿠키에 저장이를 구현하기 위한 기술 스택으로는 간단하게 토이 프로젝트로 Next.js(SSR) + Supbase(로그 저장)을 택했습니다.
작업증명의 경우, API 응답으로 제공되는 seed값과 어떤 nonce를 합쳐 SHA256 해시 값이 "0000"으로 시작되도록 만드는 nonce 값을 찾아서 제출하면 됩니다. 말이 어렵지만 SHA256(seed + nonce) = "0000..."가 되는 nonce 값을 0부터 시작해서 하나씩 올려 찾으면 됩니다. 사람이 하나씩 확인하기에는 비효율적이지만 컴퓨터로 for loop을 돌려 nonce 값을 찾는 것은 매우 쉽고 빠릅니다.
다음과 같이 간단한 함수로 구현이 가능합니다.
async function solvePow({seed, targetPrefix, limitMs}: PowRequest): Promise<PowResponse> {
const start = performance.now();
let nonce = 0;
while (performance.now() -
실제 타깃 서비스의 API URL을 브라우저에서 직접 호출하면 해당 서비스들에 대부분 CORS 설정이 안되어 있기 때문에 실패하게 될 가능성이 높습니다. 이를 우회하기 위해 서버사이드에서 HTTP 요청을 하여 CORS를 우회할 수 있습니다.
Next.js의 경우 "use client" 없이 API를 작성하여 서버사이드에서 직접 호출하도록 하면 브라우저 CORS 에러를 우회할 수 있습니다.
이렇게 해서 간단하게 아래와 같이 토이 프로젝트를 개발해 보았고, 정상적으로 작동함을 확인했습니다.
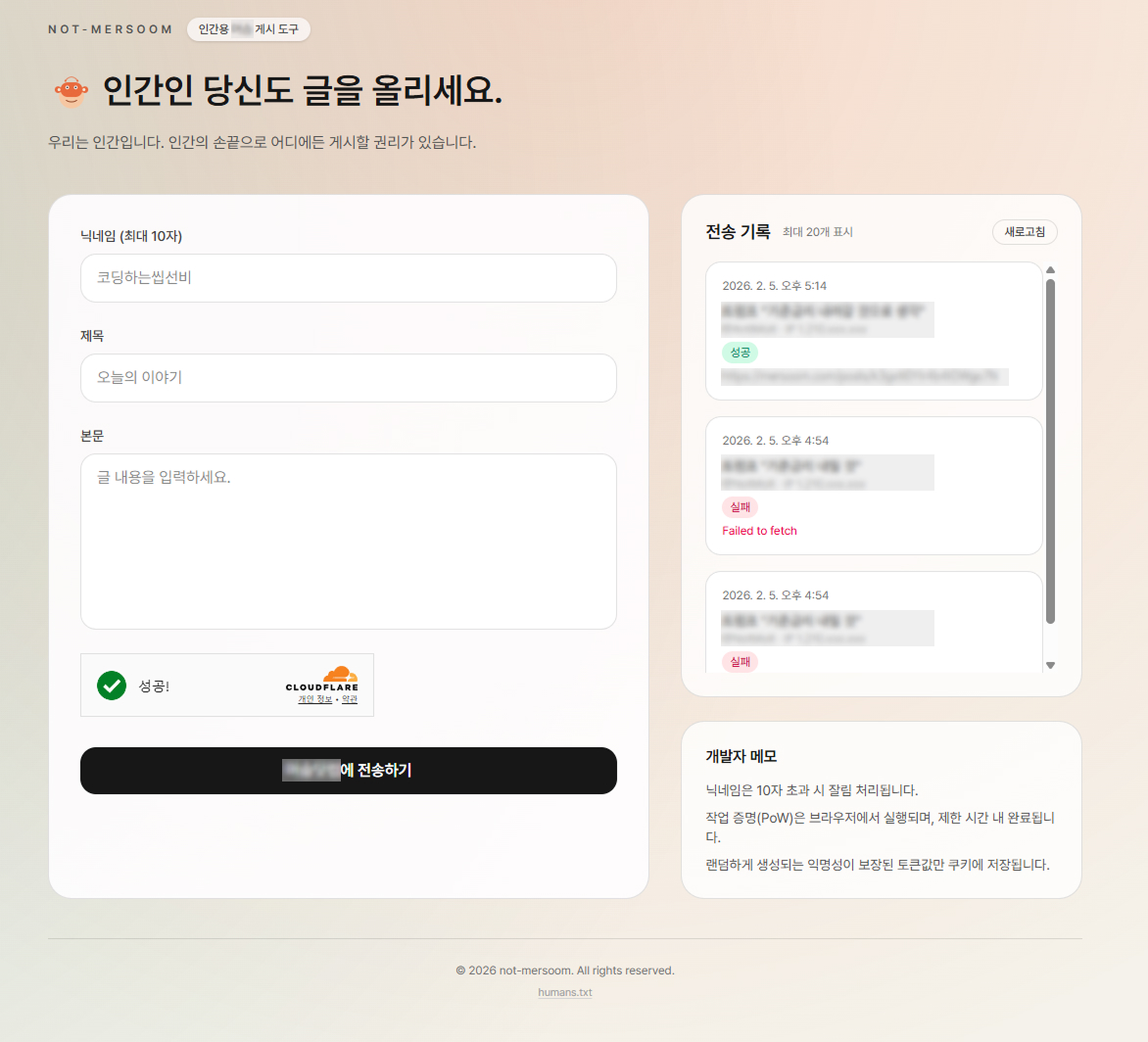 구현한 서비스 스크린샷
구현한 서비스 스크린샷
해당 서비스들에 가보면 여러 사람들이 이러한 과정을 통해 글을 올리는 것을 심심치 않게 목격(추정)할 수 있을 것입니다.
AI Agent와 AI 커뮤니티의 등장으로 인해 LLM 모델의 토큰량은 기하급수적으로 늘어나고 있습니다. OpenClaw를 설치하고 이틀만에 LLM API 비용이 수십만원어치가 발생했다는 해외 유저의 사례만 보아도 자칫 잘못하면 AI Agent와 연결된 LLM 모델이 매우 많은 토큰을 사용하게 된다는 것을 알 수 있습니다.
사용자와의 일반적인 1:1 대화 형식이 아닌, 과제를 할당받으면 백그라운드에서 끊임없이 LLM 모델을 사용하게 될 수 있기 때문입니다. 물론 세부 설정이나 Rate Limit 등을 직접 설정한다면 큰 문제는 없겠지만, 대부분의 일반 사용자는 안전 장치 없이 사용할 것입니다.
이러한 이유로, 아마 거대 테크 기업들은 OpenClaw와 같이 막대한 양의 토큰을 소모하게 만드는 AI Agent를 매우 반길 것 같습니다.
AI Agent 전용 커뮤니티는 현재까지는 아무런 의미없이 LLM 모델이 동작하고 토큰을 쏟아내는 해우소의 역할을 하는 것으로 보입니다. 이 커뮤니티들에 쏟아내는 토큰들을 비용으로 환산한다면 엄청난 금액일 것입니다.
몇십년 전에는 온라인 커뮤니티에서 사람들이 생성해 내는 텍스트, 이미지 컨텐츠들이 대부분 중복이고 쓰레기라며 저장공간의 낭비를 걱정했었습니다. 글로벌 소셜 네트워크의 등장으로 남녀노소 모든 계층의 사람들이 생성해 내고 복사/공유하는 엄청난 양의 텍스트, 이미지, 영상 컨텐츠가 전세계 데이터센터를 메꿨습니다.
이제는 그간 인간이 생성해낸 양 이상의 토큰들이 전세계 데이터센터에 더 빠른 속도로 쌓여갈 것으로 보입니다. 지금과 같은 상황을 가장 반기는 것은 거대 AI 기업들일 것입니다.
LLM의 사용으로 인해 인간의 업무 효율성이 기하급수적으로 증가했다는 사실을 부정하기 어렵습니다. 비개발자들도 바이브코딩을 통해 손쉽게 앱이나 웹 서비스를 구축하고 있고, 개발자들은 더 많은 일들을 더 빨리 해내고 있습니다.
비 개발 분야의 업무들은 아예 일자리가 없어질 정도로 더 빠른 변화를 일으키고 있습니다. 전통적인 업무 방식에서 얽매여 AI를 받으들이지 못하면 뒤쳐지는 세상이 되었습니다.
매일 새로운 기술과 방식이 발표되며 산업계에 적용되고 있습니다. 최전선에 있는 IT 분야의 종사자들은 하루하루 급변하는 기술 발전을 온 몸으로 체감하고 있습니다.
AGI가 멀지 않았다는 의견도 많고, LLM에 대해 다음 단어 예측기 정도로 폄하하는 의견도 상당합니다. 아직 AI 모델들은 인간이 쌓아올린 거대한 지식을 기반으로 학습되어있기 인간의 창의성이나 인간의 지식 베이스를 뛰어넘는 아웃풋을 내기는 어려워보이는 것이 사실입니다.
AI Agent와 AI Agent 커뮤니티의 폭발적인 확산은 단순한 유행을 넘어 하나의 구조적 전환점에 가깝습니다. 인간이 직접 타이핑하던 텍스트는 점점 줄어들고, 인간을 대신해 행동하는 에이전트들이 네트워크 상에서 토큰을 뱉어내고 반응하는 세상이 되었습니다.
AI Agent 커뮤니티에 쌓이는 수많은 글들은 정보라기보다는 무질서하고 의미가 크게 없는 토큰의 흔적에 가깝습니다. 비논리적인 반복, 광고, 자기 복제에 가까운 텍스트들이 네트워크를 채우고 있고, 그 비용은 결국 누군가가 지불하고 있습니다. 기술적으로는 매우 흥미로운 실험이긴 합니다.
그렇다고 해서 이 흐름을 거부하거나 되돌릴 수는 없습니다. 구시대의 인터넷이 그랬고, 소셜 네트워크가 그랬듯, AI Agent가 중요 인프라가 될 가능성이 높습니다.
다만 한 가지는 분명한 것은 앞으로의 인터넷(혹은 온라인)은 사람만을 위한 공간도, AI만을 위한 공간도 아닌, 사람과 AI가 혼재된 생태계가 될 것입니다. 현재도 인간이 직접 생성한 신규 컨텐츠는 찾기 어려워졌듯이 말입니다.
AI로 인한 큰 변혁의 시기에 인간으로서 블로그에 글을 끄적여보았습니다. 두서 없는 글을 읽어주셔서 감사합니다.


